

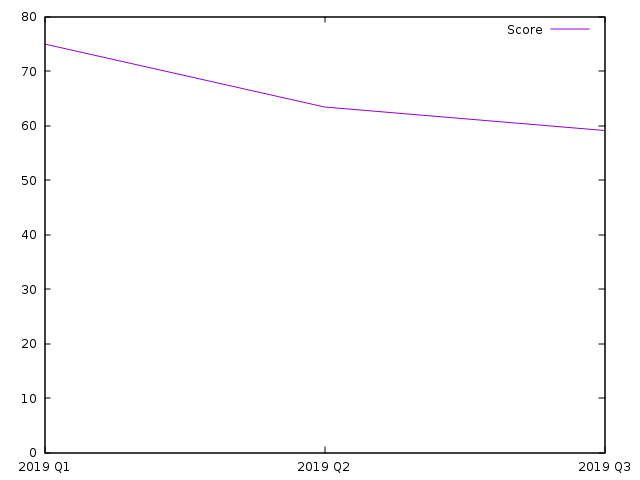
2019年前三季度自评分数为74.97,63.40,和59.09(不及格!)。因呈现再而衰,三而竭的趋势,故取名蹉跎指数。
蹉跎指数的理论基础来源于《斯坦福大学人生设计课》(Designing Your Life) 一书中的仪表盘方法 (PDF) 。结合自己的实际情况,做了两个改动:
- 将分类从四个增加到七个,
- 将主观打分改为基于时间的客观评价。
打分有两个目的,一是横向比较不同分类,分析那些方面做得不够;二是纵向比较不同时期的发展趋势。但是主观打分很难维持同样的标准,所以尽管多年前就读过这本书,却一直没有采用。
幸好,我有计时数据,之前每个月也会汇总,看看花了多少时间在不同分类上。缺点是横向纵向比较都不方便,首先,各个分类需要的时间不同,比较绝对数字没有意义。其次,分别跟踪七个不同分类的趋势有些杂乱。
解决之道的灵感来自F1 score(这大概是我学习人工智能最大的收获)。F1 score将两个不同的分数整合在一起,以便比较。而我所需要的,正是将七个分数整合在一起的办法。从F1 score,我找到了调和平均数 (Harmonic mean) ,准确的说,是加权调和平均数,先把不同类别所花时间调整到同样的区间(类似于深度学习的feature scaling),然后计算调和平均数。
调和平均数的一个特性是它的上限受制于输入数据中最小的一个,比如如果我的某项评分为10,那么蹉跎指数则不可能超过它的七倍(因为有七个类别),即70,不管其它项的分数多么优秀。从下图的数据可以看出,最近两个季度蹉跎的原因是对钱的重视不够。
整个计算中最不客观的部分是权重。首先,根据之前的记录给第一季度主观打分,范围在[70, 80],然后用各项分数除以所花时间,得到权重。这虽然导致蹉跎指数的计算过程没有完全剔除主观因素,但是因为使用同样的权重保证了前后一致,可以做纵向比较。
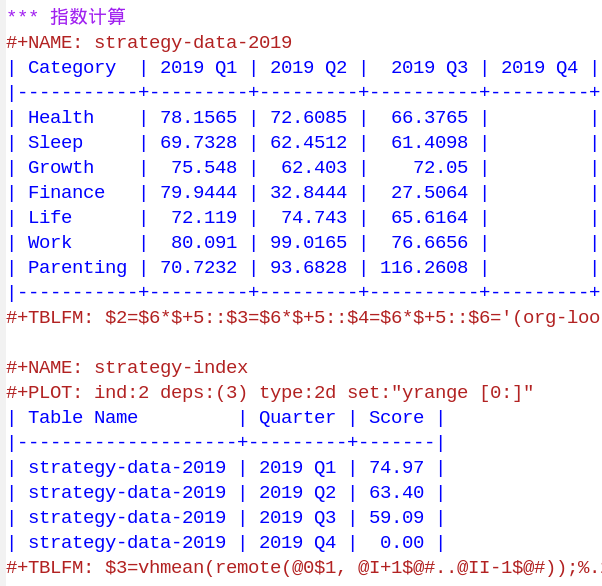
最后提一下计算过程,因为所有时间记录都使用Emacs org-mode管理,所以汇总表格也采用org-mode内置的表格计算,具体实现以后再详细介绍。实际上,当初前两个季度的数据是手工计算的,直到最近才实现了自动化。
有了蹉跎指数,时间记录变得更有价值,成为今后时间安排的重要参考数据,帮助自己过上中意的生活。穷则不会后悔对钱不够重视,富则不会遗憾没有多陪家人。





